OmniHuman-1: ByteDance's New AI for Realistic Human Video Generation
A team at ByteDance has introduced OmniHuman-1, an AI model capable of generating realistic human videos from a single portrait image and an audio input. The generated videos exhibit impressive naturalness and fluidity.
Research Paper Details
- Title: OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
- Links:
- Paper: https://arxiv.org/pdf/2502.01061v1
- Project Page: https://omnihuman-lab.github.io/
- Note: The paper is not open-sourced, potentially for commercial reasons.
Abstract
End-to-end human animation, particularly audio-driven talking head generation, has seen significant progress. However, scaling these methods like general-purpose video generation models has been a challenge, limiting their real-world application. This paper introduces OmniHuman, a Diffusion Transformer-based framework. It scales data during training by incorporating motion-related conditions. The framework uses two training principles for these mixed conditions, along with a matching model architecture and inference strategy. This allows OmniHuman to leverage data-driven motion generation, creating realistic human videos. OmniHuman supports various portrait types (close-ups, half-body, full-body), speech and singing, interactions with objects, challenging poses, and adapts to different image styles. Compared to existing audio-driven methods, OmniHuman generates more realistic videos and offers greater input flexibility, supporting audio, video, and combined driving signals.
Background
The rise of video diffusion models like DiT has significantly advanced general video generation, largely due to large-scale training data. End-to-end human animation models have followed, but they often rely on highly curated datasets, limiting their applicability. For instance, many audio-conditioned models focus on facial or head animation, while pose-conditioned models are restricted to frontal views and static backgrounds. Simply increasing data size for human animation isn't always effective. Audio, for example, primarily relates to facial expressions, with less connection to body pose or background movement. Original training data often requires filtering to reduce irrelevant factors and is cleaned based on lip-sync accuracy. Pose-conditioned models also need extensive filtering, cropping, and cleaning, discarding valuable motion patterns and hindering dataset scaling.
Contributions
- The paper introduces the OmniHuman model, a hybrid-conditioned human video generation model. It uses an omni-conditions training strategy to integrate various motion-related conditions and their corresponding data. Unlike methods that reduce data through strict filtering, this approach benefits from large-scale mixed-condition data.
- OmniHuman generates realistic and vivid human motion videos, supporting multiple modalities and performing well across different portrait types and input aspect ratios.
- OmniHuman significantly improves hand gesture generation, a challenge for previous end-to-end models, and supports various image styles, outperforming existing audio-conditioned human video generation methods.
Technical Approach
The OmniHuman framework consists of two main parts:
- OmniHuman Model: Based on the DiT architecture, supporting simultaneous conditioning on multiple modalities.
- Omni-Conditions Training Strategy: Progressive multi-stage training based on the correlation between conditions and motion.
Framework Overview
The OmniHuman model builds upon a pre-trained Seaweed model (using MMDiT), initially trained on general text-video pairs for text-to-video and text-to-image tasks. Given a reference image, the model generates human videos using one or more driving signals, including text, audio, and pose. It uses a causal 3DVAE to project videos into a latent space and employs a "flow matching" objective to learn the video denoising process. A three-stage hybrid conditioning post-training method gradually transforms the diffusion model from a general text-to-video model into a multi-conditional human video generation model.
Omni-Conditions Design
- Driving Conditions:
- Audio: Uses a wav2vec model to extract acoustic features, compressed with an MLP and concatenated with adjacent timestamps to generate audio tokens, injected into each MMDiT block via cross-attention.
- Pose: Uses a pose-guided encoder to encode driving pose heatmap sequences, concatenating the resulting pose features with adjacent frames to obtain pose tokens, then stacking them with the noisy latent vectors along the channel dimension, inputting them into a unified multi-conditional diffusion model.
- Appearance Conditions: A strategy is introduced to preserve the identity and background details from the reference image. The original denoising DiT backbone is re-used to encode the reference image. The reference image is encoded into a latent representation via VAE, flattened into a token sequence along with the noisy video latent vectors, and input into DiT. 3D RoPE modification helps the network distinguish between reference and video tokens. To support long video generation, motion frames are used, and their features are connected with the noise features.
Omni-Conditions Training Expansion
Due to the multi-conditional design, model training can be divided into multiple tasks. Training follows two principles:
- Tasks with stronger conditions can leverage tasks with weaker conditions and their data to achieve data expansion during model training.
- The stronger the condition, the lower the training proportion should be.
Based on this, three training stages are constructed, gradually introducing different conditions and adjusting the training proportion so that the model can effectively use mixed-condition data for training.
Inference Strategy
In audio-driven scenarios, all conditions except pose are activated. In pose-related combinations, all conditions are activated, but audio is disabled when only pose is driving the animation. Classifier-Free Guidance (CFG) is used during inference, and a CFG annealing strategy is proposed to balance expressiveness and computational efficiency, reduce wrinkles, and ensure expressiveness. The last five frames of the previous segment are used as motion frames to ensure temporal coherence and identity consistency in long videos.
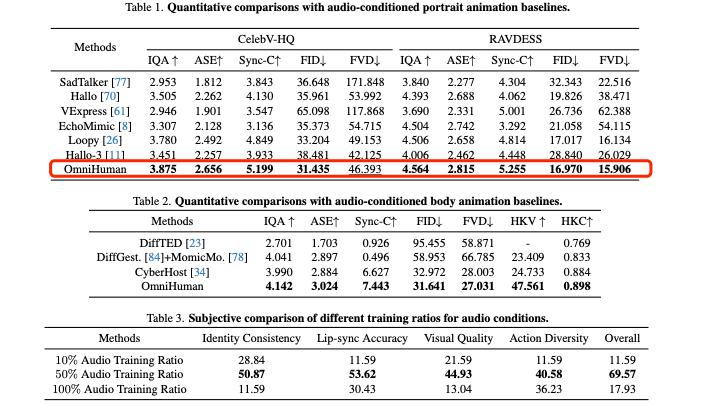
Experimental Results
- Comparison with Existing Methods: OmniHuman demonstrates superior performance compared to leading specialized models in both portrait and body animation tasks, achieving optimal results on almost all evaluation metrics. It also supports various input sizes, scales, and body proportions.
- Ablation Study of Full-Condition Training: Analysis of the two principles of full-condition training reveals that the proportion of audio-condition-specific data and weaker-condition data (such as text) significantly affects the final performance, with a 50% proportion of weaker-condition data producing satisfactory results. The pose condition ratio also impacts model performance, with a final pose ratio set to 50%. The reference image ratio is also important for generated video quality, with a higher ratio ensuring better alignment between the generated output and the quality and details of the original image.
- Extended Visual Results: OmniHuman is compatible with multiple input images, maintains the input motion style, performs well in object interaction, and can perform pose-driven or combined pose-and-audio-driven video generation.


Conclusion
The paper presents OmniHuman, an end-to-end multi-modal conditional human video generation framework that can generate human videos based on a single image and motion signals (such as audio, video, or both). OmniHuman uses a mixed-data training strategy for multi-modal motion conditions, leveraging the scalability of mixed data to overcome the scarcity of high-quality data faced by previous methods. It significantly outperforms existing methods and can generate highly realistic human videos from weak signals (especially audio). OmniHuman supports images of any aspect ratio (portrait, half-body, or full-body) and provides realistic, high-quality results in various scenarios.